Readwise Reader is what I've been looking for
Readwise Reader is a new read-it-later app with an integrated web highlighter. On top of this combination, they added many useful features that make it a powerful tool in knowledge management and digital gardening. I’m excited by its potential to make reading web content easier and more useful. If you have a personal knowledge management system, Reader is the most promising tool for collection and consumption.
What is it?
Readwise Reader is an enhanced read-it-later app currently in open beta. For those familiar with Instapaper or Pocket, the functionality is similar. You can clip and store web content for reading later within the app. Where Reader shines though is its web highlighter which allows in-page or in-app highlighting of a piece of content, similar to the way hypothes.is works. These highlights can then be annotated or exported. Often a blog post boils down to a few key sentences which you can highlight, giving you more context later on why you stored or read that article.
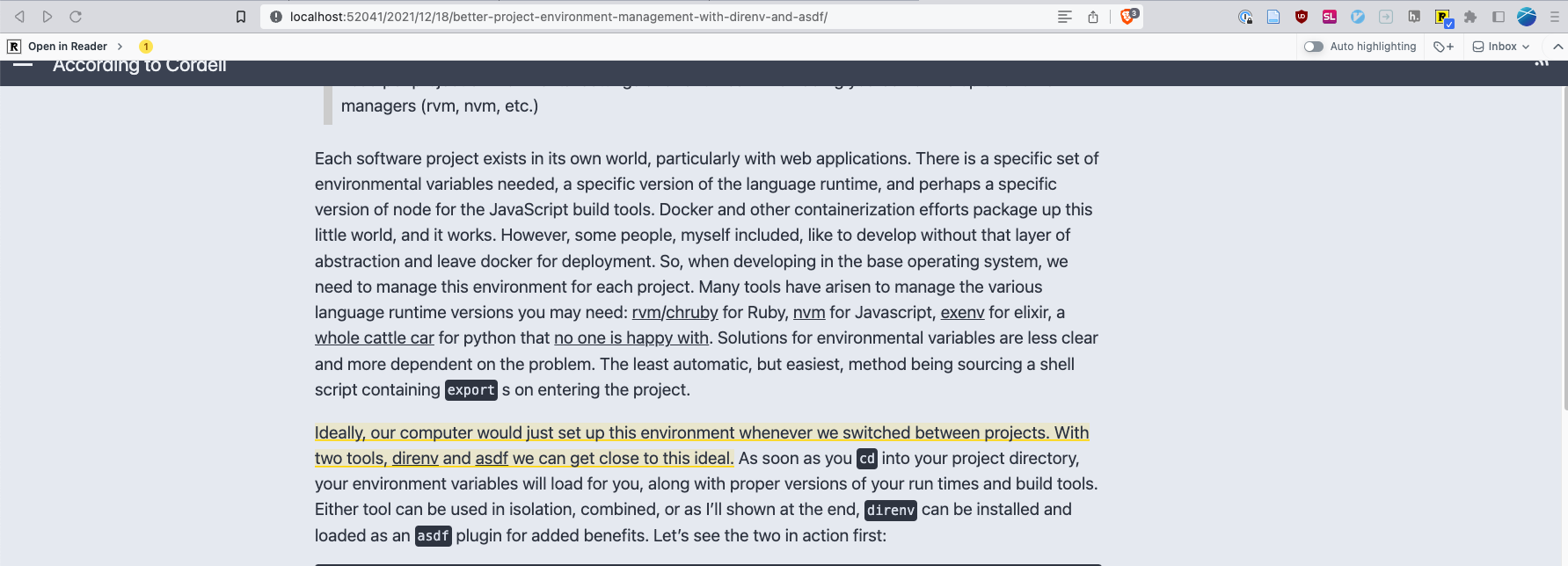
Figure 1: Highlighting content directly on a web page
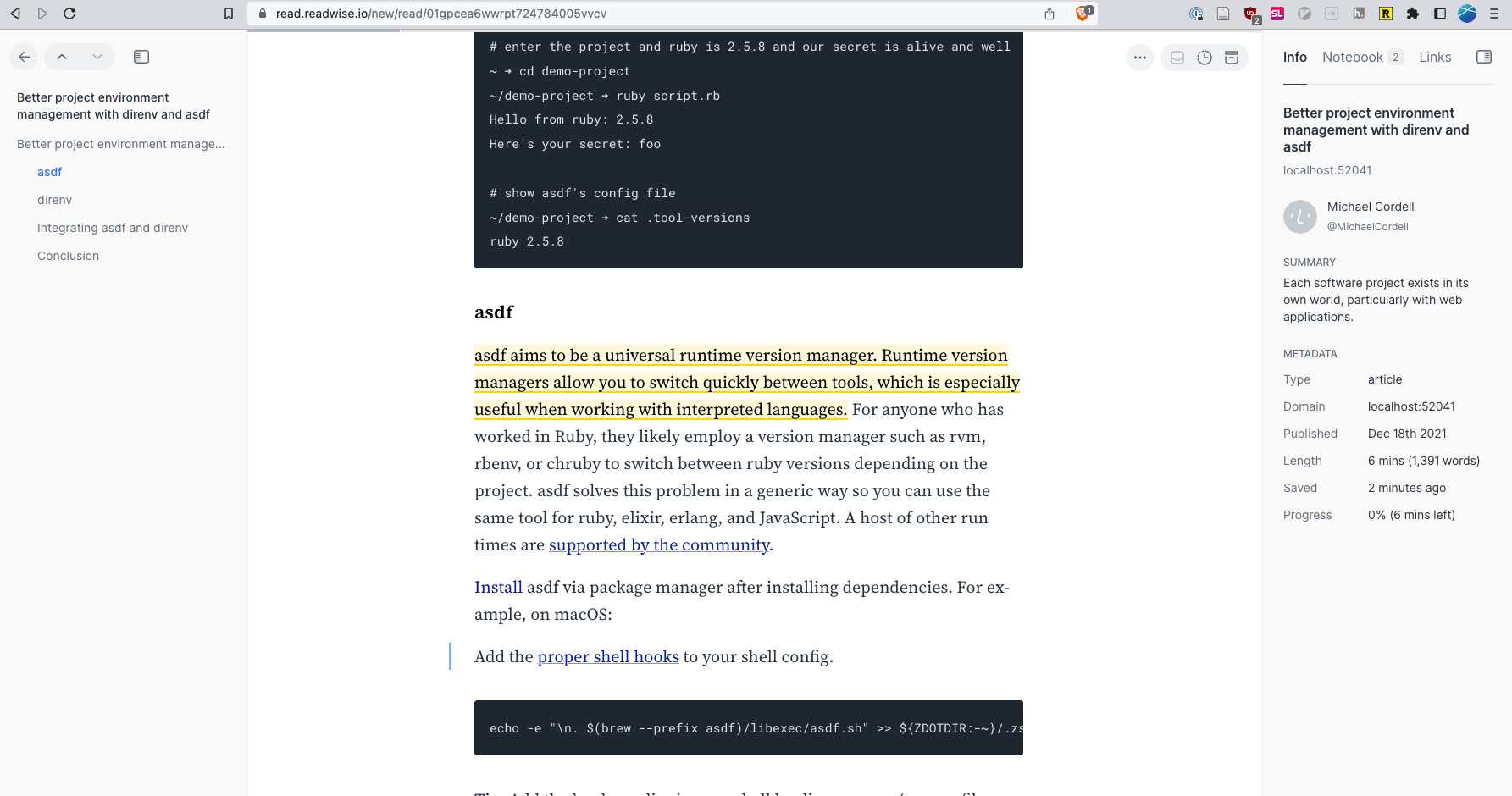
Figure 2: Highlighting content within the Reader app
The read-it-later and highlighting functionality alone would be enough, but the Readwise folks layered on several well-thought out features. There is a ChatGPT-like feature, called Ghost Reader which allows you to generate a summary of an article or ask questions of the text. There are strong “context-features” for the content you save. You can tag content and individual highlights so that they can be recalled later. More importantly, there is rough automatic attribution for the author and publishing time. This is always a key piece of context I like to have when consuming content or reviewing previously captured/read content. One final killer feature is text-to-audio, you can listen to a blog post while walking or commuting.
Why am I excited about Reader?
Reader scratches an itch that I’ve already tried to solve myself. Roughly two years ago, I built my own capture app focused on attribution and context. I’ve been using it steadily for the last two years and had about a thousand articles saved. For a powerful endorsement, after using Reader for about a month, I’ve retired my app. Here’s why:
Reader is relatively open: Reader has the potential to be a hub within knowledge collection and management. It is permissive in what it accepts, allowing you to save most readable content be it tweet threads, ePubs, PDFs, or emails. It has a rudimentary API for adding content. I was able to script up a solution to import my homebrewed collection in about a half hour. On the extraction side, you can connect Reader to a variety of note taking systems (Notion, Obsidian, Evernote, Roam). There is also the ability to export to markdown, which gives highlights a universal portability. For example, I use org-roam so I can get my highlights in by copy the markdown to clipboard and then in terminal:
pbpaste | pandoc -f markdown -t org | pbcopy
Allowing me to paste into what org-mode note I’m working on. Finally, Reader obviously connects up to the original Readwise application, allowing you to use spaced repetition learning or just daily digests to review your saved material.
Solving the collection, collation, and reading part of the knowledge management problem is valuable, integrating deeply and making the data available even more so. I hope the Reader product team will continue to build out the API and maintain open export formats. This approach certainly hasn’t hurt products such as Notion.
Reader makes the reading experience easy: The user experience for reading is delightful, particularly for a beta product. It’s easy to find an article within my stored content, and there are multiple ways to consume it: highlighting in page, read/highlighting in the app, having it read to me, or even generating an auto summary. The iOS application is still in Beta, but I have had no problems reading on my phone or iPad.
What else would I like to see?
While the app is incredibly strong for an open beta, I would like to see the following features added as it matures:
- Better attribution and metadata management
- This is a hard problem with the myriad formats available for authors to attribute (JSON-LD, meta tags, RDFa, etc.). Not to mention the contingent that does none of the above. In those cases, it would be useful to have rules (e.g. this domain is a blog written by so and so, the publish date can be picked up from the URL).
- Support for citation
- One of the key parts of having attribution is the ability to cite in future writing. It would be nice if you could click-copy a BibTex citation.
- Ratings for articles
- I could probably hack this together using their tag system, but it would be nice to have a separate field for it.
- Better API
- Support for Newsletter Aggregation Emails: For example, hackernewsletter or Software Lead Weekly